
SVLR Architecture.

Object detection with VLM and Zero-Shot Segmentation.

Object detection proceedings.
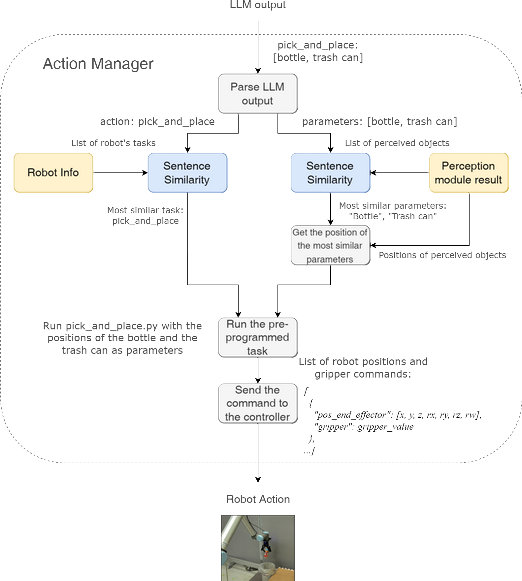
The integration of language instructions with robotic control, particularly through Vision Language Action (VLA) models, has shown significant potential. However, these systems are often hindered by high computational costs, the need for extensive retraining, and limited scalability, making them less accessible for widespread use. In this paper, we introduce SVLR (Scalable Visual Language Robotics) 1 , an open-source, modular framework that operates without the need for retraining, providing a scalable solution for robotic control. SVLR leverages a combination of lightweight, open-source AI models including the Vision-Language Model (VLM) Mini-InternVL, zero-shot image segmentation model CLIPSeg, Large Language Model Phi-3, and sentence similarity model all-MiniLM to process visual and language inputs. These models work together to identify objects in an unknown environment, use them as parameters for task execution, and generate a sequence of actions in response to natural language instructions. A key strength of SVLR is its scalability. The framework allows for easy integration of new robotic tasks and robots by simply adding text descriptions and task definitions, without the need for retraining. This modularity ensures that SVLR can continuously adapt to the latest advancements in AI technologies and support a wide range of robots and tasks. SVLR operates effectively on an NVIDIA RTX 2070 (mobile) GPU, demonstrating promising performance in executing pickand-place tasks. While these initial results are encouraging, further evaluation across a broader set of tasks and comparisons with existing VLA models are needed to assess SVLR's generalization capabilities and performance in more complex scenarios.
@INPROCEEDINGS{10870971,
author={Samson, Marie and Muraccioli, Bastien and Kanehiro, Fumio},
booktitle={2025 IEEE/SICE International Symposium on System Integration (SII)},
title={Scalable, Training-Free Visual Language Robotics: a modular multi-model framework for consumer-grade GPUs},
year={2025},
volume={},
number={},
pages={193-198},
keywords={Visualization;Robot kinematics;Scalability;Large language models;Pipelines;Robot control;System integration;Cognition;Object recognition;Robots},
doi={10.1109/SII59315.2025.10870971}}